
Turtlebot3 & Monocular Range Sensing
December 10, 2021
Overview
During my final fall quarter at Northwestern, I learned about a new machine learning algorithm called the Gaussian Process. This algorithm essentially is a machine learning model used to predict both the result and measure how confident in the result the machine is. In the experiment, I attempt to use the Gaussian Process to predict the depth of the robot’s surrounding based on the images read in from a raspberry pi camera. I then deploy the results to SLAM, which would allow the robot to produce a map of its surrounding environment.
More technical details of the project can be found in this Github repository.
The idea behind the Gaussian Process Model was inspired by this paper. In order to train the model, I first had to capture images from the raspberry pi camera as well as the corresponding distances from the LIDAR sensor. I then unwarped and apply PCA to the image to reduce the dimension of each column of unwarped image. I then trained the Gaussian Process Model using the reduced dimension image column dataset and their corresponding distances. I then applied the model to the camera stream coming from the raspberry pi to determine the distance live and send the results to the SLAM node. In ordered to see the algorithm in action, I modified the turtlebot3 as shown in the picture on the right to be able to capture images of its surrounding and then ran SLAM to compare the resulting maps which were generated.
System Overview
As shown on the right, I modified the stock turtlebot3 robot to include an additional waffle plate plateform. This additional platform in the middle housed a camera mount and the raspbery pi camera. In additional, I attached a convex mirror beneath the top plate and adjusted to make sure the camera was able to capture the reflection coming off of the mirror. My goal with the project is to essentially have the robot be able to sense distances to obstacles without using the LIDAR, but instead from the reflection coming off of the mirror and a Gaussian Process machine learning model. This design was inspired by Figure 3 in the paper I read
Here is a system diagram highlighting how the camera and mirror impact the generation of the map. The two systems run seperately.
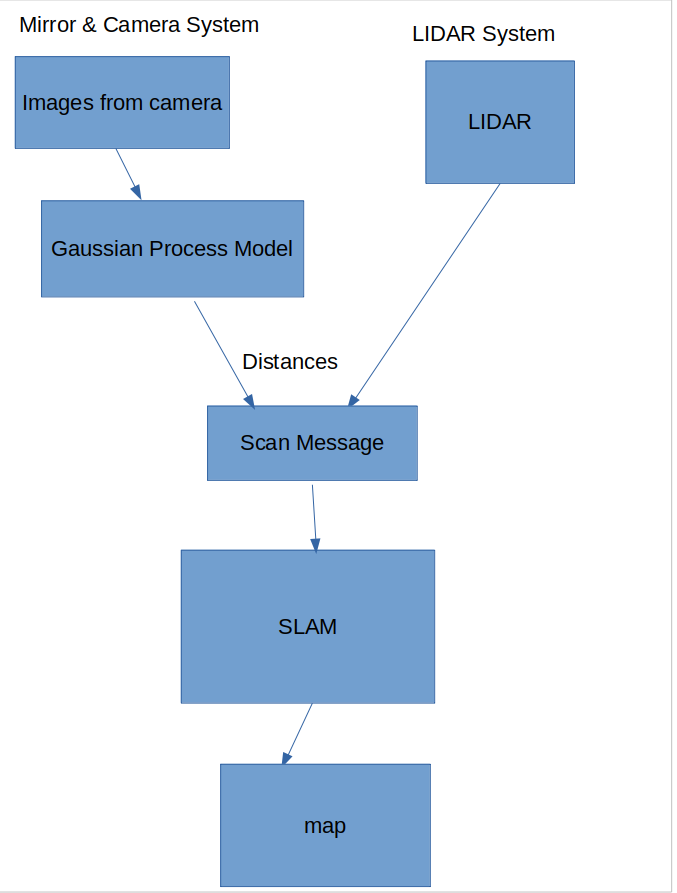
Here are some results I got
Training the Gaussian Model
Initial Setup
Initial Image Setup
I built up an enclosed space on the floor with obstacles that the turtlebot would want to drive over. In order to train the robot, I would drive it around the enclosed area until I deemed it captured enough data regarding to the number of images and LIDAR data
Video of robot driving around the obstacle for training
Fisheye image from raspberry pi camera

Unwarped image

After saving the dataset into a folder as well as the corresponding distances into a csv file, I sent the data into the Gaussian Process Model
Training the model
Before the images were sent to the Gaussian Process Model, each of the image’s column length was first reduced in column length from 420 pixels down to 6 pixels using PCA. After the images were reduced, they along with the associated observed distance values were sent into the Gaussian Process Model, which would use it to train itself. Each column had an associated depth value, which was determined from the LIDAR readings. Each image had 360 columns.
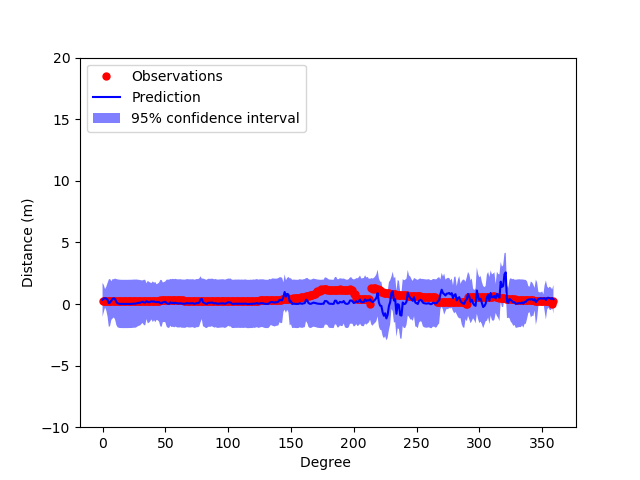
Gaussian Process Model after training on 360 columns (1 image)
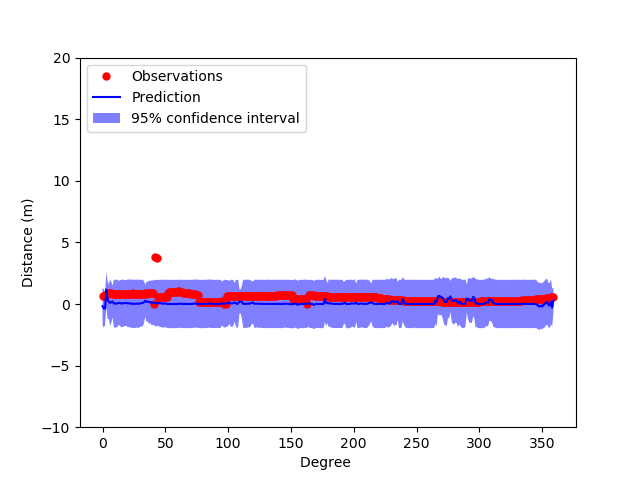
Gaussian Process Model after training on 720 columns (2 images)
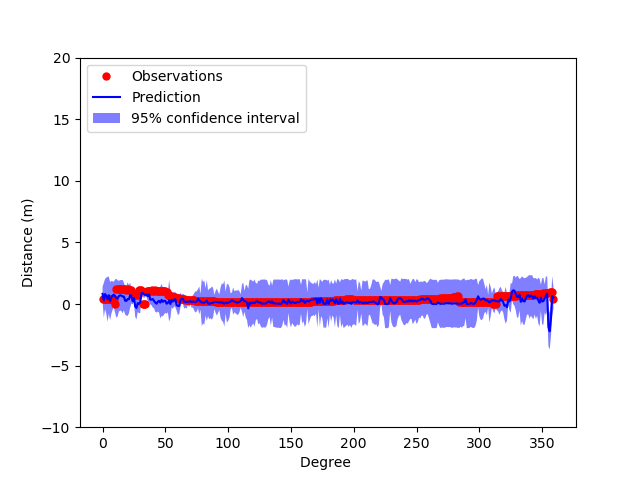
Gaussian Process Model after training on 1800 columns (5 images)
Gaussian Process Model after training on 3600 columns (10 images)
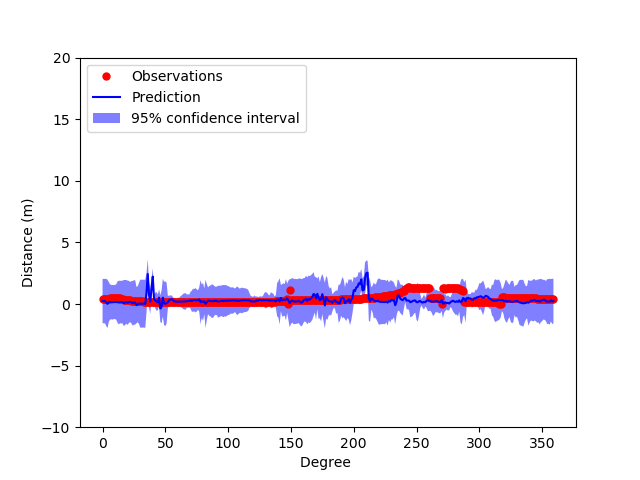
From the graphs, it can be shown that the more images the model trains on, the more accurate the Gaussian Process Model is able to predict and the more confident it is with its prediction. This shows that if there were more images(ex 600 images), then the model theoretically would be pretty robust in predicting depth given the image itself.
Testing the model
To test the model, I deployed the robot on a different obstacle course to see how well the map generated from SLAM would compare with that generated from the LIDAR and here were some of the results
Initial Setting of the robot

LIDAR Test
IRL Video
Video Generating Map
Gauss Test
IRL Video
Video Generating Map
Analysis of Result

The LIDAR map is on the left, and the Gaussian Process map is on the right.
The maps shown above unfortunately do not show that the Gaussian Process was able to form a map that was able to generate a map that had any cohesive information, let alone similar to what the LIDAR was able to generate. What I expected in the experiment from the Gaussian Process is a map that I could discern a room from. There were several factors that might explain why the experiment wasn’t successful. One reason being the mount of processing power required to train a Gaussian Process Model. When training the model, I frequently ran into issue regarding memory, which when it came down to was the implementation of the Gaussian Process training algorithm in scikit-learn. Since the paper didn’t explicitly state how many columns each image had, I assume there would be 360 columns in each image to match the resolution coming from the LIDAR. This lead to the algorithm in scikit-learn attempting to allocate 174GB of memory for its array when it was training the model, which seems very unreasonable. If I were to implement this in the future, I would decrease the number of columns in the images to alleviate the memory due to the fact that the paper’s implementation use a SICK laser range finder, which doesn’t have the same resolution as the LIDAR on the turtlebot3. Another way I could overcome the memory issue could be using a different library to run the Gaussian Process like the GPy library, or possible run the code in C or C++ to better manage the memory. Another reason could be the mirror used in the experiment. Due to accessiblilty to parts, I was not able to source a mirror that had an optimal focal length to the turtlebot, which might have affected how far the turtlebot3 camera was actually able to see. In the future, I would like to spend more time determining what the best focal length used that would be able to give the best range for the camera to see and go and possible find it or design the mirror itself. Another reason could be down to the inefficiencies of the algorithm itself. Gaussian Process doesn’t perform well when it comes to training on images, and there are other machine algorithm out there more suitable to train on images (ex.Convolution Neural Networks).